To create a child process in Linux/Unix , you can use clone(2) or fork(2). We use clone(2) is to implement multithreading and namespaces. We use fork(2) to create a “real” (child) process, i.e. separate address space and resources
In this post i will cover fork, its patterns and its pitfalls
Lets start with a simple example:
void main(void)
{
puts("hello");
fork();
puts("bye");
}
If you run this code you will see on the output:
hello bye bye
You see ‘bye’ twice because fork returns twice – when we call fork it will create a child process and returns twice – one for the parent and one for the child. On the parent process , fork returns the child process id and on the child process it returns 0
Call once, returns twice – WTF???
While running a complex algorithm , you want to use more than one processor but you need to write your code using parallel patterns. fork helps you to implement a simple pattern – fork – join
For example we have a big array (in a shared memory) and we want to calculate something in each array element, with fork its easy:
#include<stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
void main(void)
{
int x,status;
puts("parent only");
x=fork();
if(x>0){
printf("parent: do half task \n");
wait(&status);
}
else
{
printf("child: do half task \n");
exit(0);
}
puts("parent only");
}
As you can see, before the fork we have one process only, we create one child , the child do his job and exit (returning value to the parent) and the parent do his job and wait for the child to finish so after the if statement its again one process only
exit closes the process and send the result to the parent. The parent knows why its child terminated (normal or by signal) and the return value (or signal number) from the status parameter on wait system call (see man pages for details and macros)
What about the memory?
If we declare an array and change it after fork we can see that it is duplicated:
#include<stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
void main(void)
{
int x,status;
int arr[100000]={1,2,3};
x=fork();
if(x>0){
arr[1]=200;
wait(&status);
}
else
{
sleep(3);
printf("child: arr[1]=%d \n",arr[1]); // print 2
exit(0);
}
}
The child is waiting 3 seconds to make sure the parent changed the value and print the array element. the result is arr[1]=2 because each process has its own memory space. It looks like the kernel duplicate the memory on fork.
CoW (copy on write)
To save time on fork, the kernel only duplicate its mapping. For example we have 100 pages mapping for the array , the kernel will duplicate the TLB entries and change all the mapping to read only. If both processes only read, they work with shared memory but when one process try to write, it creates a page fault, the kernel trap handler copy the page and change the permission to read-write returning the program counter to the previous statement to try again.
If we measure the time of the first assignment , we will get a longer time:
...
x=fork();
if(x>0){
arr[1]=200; // page fault, copy page and update TLB
arr[2]=300; // one memory access
wait(&status);
}
To test this using Ubuntu 64 bit we add a simple assembly function
#include<stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
static __inline__ unsigned long long rdtsc(void)
{
unsigned hi, lo;
__asm__ __volatile__ ("rdtsc" : "=a"(lo), "=d"(hi));
return ( (unsigned long long)lo)|( ((unsigned long long)hi)<<32 );
}
void main(void)
{
int x,status;
long long t1,t2,t3,t4;
int arr[100000]={1,2,3,4,5};
x=fork();
if(x>0){
t1=rdtsc();
arr[1]=20;
t2=rdtsc();
arr[2]=30;
t3=rdtsc();
arr[3]=40;
t4=rdtsc();
printf("t1=%lld\n",t1);
printf("t2=%lld\n",t2);
printf("t3=%lld\n",t3);
printf("t4=%lld\n",t4);
wait(&status);
}
else
{
printf("child \n");
exit(0);
}
puts("parent only");
}
Output:
t1=40593170692468 t2=40593170692600 t3=40593170692640 t4=40593170692676
As you can see from the output , the first time we write take 3 times longer as a result of a page fault
Fail to fork?
fork fails in some situations: if we reached the maximum user processes allowed (see ulimit -a) , out of memory, no MMU and more (see man page)
It also fails if the parent process consume more than 50% of the system memory. Let take an example:
void main(void)
{
int x,status;
int arr1[50000000];
puts("bye");
memset(arr1,0,sizeof(arr1));
x=fork();
...
}
The program declares a 200MB array and clear it using memset to make it map to physical memory. As we saw, on fork the memory is not duplicate but the system check if we have the required free memory in case the child will write. If the system doesn’t have 200MB free, fork will fail
The above behaviour can create a strange bug in the following situation:
- The parent fill a 200MB array and fork
- On fork, the system has 250MB free – fork returns successfully
- As a result of Copy on write mechanism , the memory is not consumed
- Another process consume 200MB
- The child process access the array elements and while trying to handle the page faults the kernel crashed
Lets test it on Qemu image with 512MB:
# cat /proc/meminfo
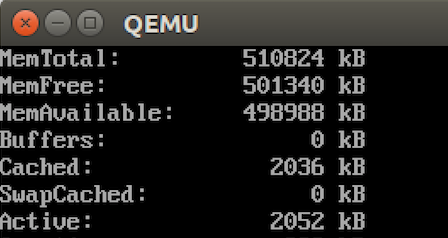
Code Example:
#include<stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
void main(void)
{
int x,status;
int arr1[50000000];
memset(arr1,0,sizeof(arr1));
x=fork();
if(x>0){
printf("fork returned:%d\n",x);
wait(&status);
else
{
int i,r;
for(i=0;i<50;i++){
memset(arr1+i*1000000,0,4000000);
sleep(30);
puts("mem");
}
}
}
Run this program and after fork:
# cat /proc/meminfo
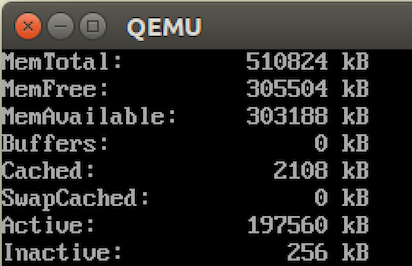
We can see the only 200MB consumed. Now run a simple program to consume more memory:
void main(void)
{
int x,status;
int arr1[52000000];
puts("bye");
memset(arr1,0,sizeof(arr1));
sleep(1000);
}
and check again:
# cat /proc/meminfo
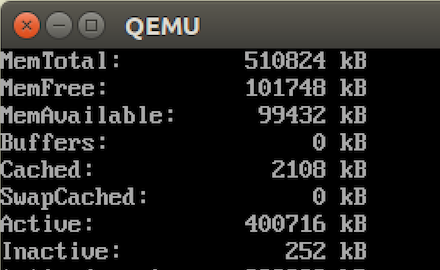
Now the child write to 4MB every 30 seconds and make a copy of the pages , when it will reach the system limit (100MB only) we will see a kernel oops:
app invoked oom-killer: gfp_mask=0x24200ca(GFP_HIGHUSER_MOVABLE), nodemask=0, order=0, oom_score_adj=0 app cpuset=/ mems_allowed=0 CPU: 0 PID: 750 Comm: app Not tainted 4.9.30 #35 Hardware name: ARM-Versatile Express [<8011196c>] (unwind_backtrace) from [<8010cf2c>] (show_stack+0x20/0x24) [<8010cf2c>] (show_stack) from [<803d32a4>] (dump_stack+0xac/0xd8) [<803d32a4>] (dump_stack) from [<8023da88>] (dump_header+0x8c/0x1c4) [<8023da88>] (dump_header) from [<801ef464>] (oom_kill_process+0x3a8/0x4b0) [<801ef464>] (oom_kill_process) from [<801ef8c0>] (out_of_memory+0x124/0x418) [<801ef8c0>] (out_of_memory) from [<801f48b4>] (__alloc_pages_nodemask+0xd6c/0xe0c) [<801f48b4>] (__alloc_pages_nodemask) from [<80219338>] (wp_page_copy+0x78/0x580) [<80219338>] (wp_page_copy) from [<8021a630>] (do_wp_page+0x148/0x670) [<8021a630>] (do_wp_page) from [<8021cdd8>] (handle_mm_fault+0x33c/0xb00) [<8021cdd8>] (handle_mm_fault) from [<80117930>] (do_page_fault+0x26c/0x384) [<80117930>] (do_page_fault) from [<80101288>] (do_DataAbort+0x48/0xc4) [<80101288>] (do_DataAbort) from [<8010dec4>] (__dabt_usr+0x44/0x60) Exception stack(0x9ecc3fb0 to 0x9ecc3ff8) 3fa0: 77aaa7f8 00000000 0007c0f0 77dff000 3fc0: 00000000 00000000 000084a0 00000000 00000000 00000000 2b095000 7e94ad04 3fe0: 00000000 722ed8f8 00008678 2b13c158 20000010 ffffffff Mem-Info: active_anon:124980 inactive_anon:2 isolated_anon:0 active_file:23 inactive_file:31 isolated_file:0 unevictable:0 dirty:0 writeback:0 unstable:0 slab_reclaimable:457 slab_unreclaimable:598 mapped:46 shmem:8 pagetables:323 bounce:0 free:713 free_pcp:30 free_cma:0 Node 0 active_anon:499920kB inactive_anon:8kB active_file:92kB inactive_file:124kB unevictable:0kB isolated(anon):0kB isolated(file):0kB mapped:184kB dirty:0kB writeback:0kB shmem:32kB writeback_tmp:0kB unstable:0kB pages_scanned:56 all_unreclaimable? no Normal free:2852kB min:2856kB low:3568kB high:4280kB active_anon:499920kB inactive_anon:8kB active_file:92kB inactive_file:124kB unevictable:0kB writepending:0kB present:524288kB managed:510824kB mlocked:0kB slab_reclaimable:1828kB slab_unreclaimable:2392kB kernel_stack:344kB pagetables:1292kB bounce:0kB free_pcp:120kB local_pcp:120kB free_cma:0kB lowmem_reserve[]: 0 0 Normal: 7*4kB (UE) 5*8kB (UME) 4*16kB (UME) 1*32kB (U) 2*64kB (UM) 2*128kB (UM) 1*256kB (M) 0*512kB 0*1024kB 1*2048kB (U) 0*4096kB = 2852kB 62 total pagecache pages 0 pages in swap cache Swap cache stats: add 0, delete 0, find 0/0 Free swap = 0kB Total swap = 0kB 131072 pages RAM 0 pages HighMem/MovableOnly 3366 pages reserved 0 pages cma reserved [ pid ] uid tgid total_vm rss nr_ptes nr_pmds swapents oom_score_adj name [ 723] 0 723 598 6 3 0 0 0 syslogd [ 725] 0 725 598 6 4 0 0 0 klogd [ 737] 0 737 621 42 4 0 0 0 sh [ 749] 0 749 51186 50747 103 0 0 0 app [ 750] 0 750 51186 50813 102 0 0 0 app [ 751] 0 751 51186 50752 103 0 0 0 eat Out of memory: Kill process 750 (app) score 386 or sacrifice child Killed process 750 (app) total-vm:204744kB, anon-rss:203180kB, file-rss:72kB, shmem-rss:0kB oom_reaper: reaped process 750 (app), now anon-rss:4kB, file-rss:0kB, shmem-rss:0kB
We can see the oops generated on a page fault (do_page_fault)
To avoid such cases we need to pre fault the array (read and write its content at least one element per page) immediately after fork
Files are not duplicated on fork
It is important to understand that file descriptor object are not duplicated on fork. In this way we can share resources between the child and the parent. All the anonymous objects (pipes, shared memory, etc.) can only be shared using the file descriptor. One way (the easy way) is declaring the resource before forking and the other way is sending the file descriptor using unix domain socket. If we open a regular file the child and the parent are using the same kernel object i.e. position, flags, permission and more are shared:
Example:
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/stat.h>
#include <fcntl.h>
void main(void)
{
int x,status,fd;
fd=open("./syslog1",O_RDWR);
x=fork();
if(x>0){
char buf[30];
read(fd,buf,29);
buf[30]='\0';
puts(buf);
wait(&status);
}
else
{
char buf[30];
sleep(3);
read(fd,buf,29);
buf[30]='\0';
puts(buf);
exit(0);
}
}
We open a file, read 29 chars on the parent and 29 chars on the child, the parent update the position so the child is reading where the parent ended:
Output:
Dec 16 21:46:55 developer-vir tual-machine rsyslogd: [origi
Using fork to create tasks
Because fork is weird , it is useful to be familiar with its patterns. If we want to create tasks and we have a shared code (like RTOS) but we want to create the tasks as seperate processes (not threads) so if one will fail, it will not crash all the others. We create the tasks on a loop and then the main process will wait for child exit and re spawn it.
#include "stdio.h"
#include <stdlib.h>
#include <sys/prctl.h>
#include <sys/types.h>
#include <sys/wait.h>
void task1(void)
{
prctl(PR_SET_NAME,"task1");
while(1)
{
puts("task1");
sleep(10);
}
}
void task2(void)
{
prctl(PR_SET_NAME,"task2");
while(1)
{
puts("task2");
sleep(10);
}
}
void task3(void)
{
prctl(PR_SET_NAME,"task3");
while(1)
{
puts("task3");
sleep(10);
}
}
void task4(void)
{
prctl(PR_SET_NAME,"task4");
while(1)
{
puts("task4");
sleep(10);
}
}
void task5(void)
{
int c=0;
prctl(PR_SET_NAME,"task5");
while(1)
{
c++;
if(c==5)
exit(12);
puts("task5");
sleep(3);
}
}
void (*arr[5])(void) = {task1,task2,task3,task4,task5};
int findpid(int *arr,int size,int val)
{
int i;
for(i=0;i<size;i++)
{
if(arr[i] == val)
return i;
}
return -1;
}
int main(void) {
int ids[5];
int v,i,status,pid,pos;
for(i=0;i<5;i++)
{
v = fork();
if(v == 0)
{
arr[i]();
exit(0);
}
ids[i]=v;
}
while(1)
{
pid=wait(&status);
pos = findpid(ids,5,pid);
printf("bye parent %d %d\n",pid,status);
printf("Child exist with status of %d\n", WEXITSTATUS(status));
v=fork();
if(v==0)
{
arr[pos]();
exit(0);
}
ids[pos] = v;
}
return EXIT_SUCCESS;
}
If you run the above program, you will see 6 processes running. The main process waiting for a child to exit (by signal or normal exit) and recreate it. If you send a signal to one of the children , you will see it re born.
Parent-child with different code
Sometimes we need 2 processes with parent and child relation (to send signals or share resource) but they have completely different code. In a wireless router for example we have a routing control process and a web server. We want the web server process to send a signal to the router control every time the configuration changes. We can use fork with execve to implement it:
For example: 2 processes using pipe for communication:
Parent app:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main(int argc,char *argv[])
{
char buf[20]="hello";
int fd,i=0;
fd = atoi(argv[0]);
puts("parent started:");
while(1)
{
i++;
sprintf(buf,"hello:%d",i);
write(fd,buf,10);
sleep(2);
}
return 0;
}
Compile it and call the executable parent_app
Child app:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main(int argc,char *argv[])
{
char buf[11];
int fd;
puts("child started");
fd = atoi(argv[0]);
while(1)
{
read(fd,buf,10);
puts(buf);
}
return 0;
}
compile it and call it child_app
Now write the code to connect them:
#include<stdio.h>
#include<unistd.h>
int main()
{
int arr[2];
char argv[30];
pipe(arr);
if(fork())
{
puts("starting parent");
close(arr[0]);
sprintf(argv,"%d",arr[1]);
execlp("./parent_app",argv,NULL);
}
else
{
puts("starting child");
close(arr[1]);
sprintf(argv,"%d",arr[0]);
execlp("./child_app",argv,NULL);
}
return 1;
}
compile and run it (placing the previous executables in the same directory)
We create a pipe, on the parent we close the read fd and move the write fd as a parameter to the main , on the child we do the opposite
Note that in this design if we want to change the communication type to use unix domain socket (or any other object base on file descriptor) we only need to change and compile the last program
You have other important notes about fork , add it as a comment (automatically approved)
1 thought on “Linux – fork system call and its pitfalls”
Comments are closed.
Thanks for the study
Please I need the out put for the parent and child programs